An Exact Solver for the Minimum Line Cover
of Prime-Indexed Points
An NP-Complete Sequence with a Surprisingly Flat Graph
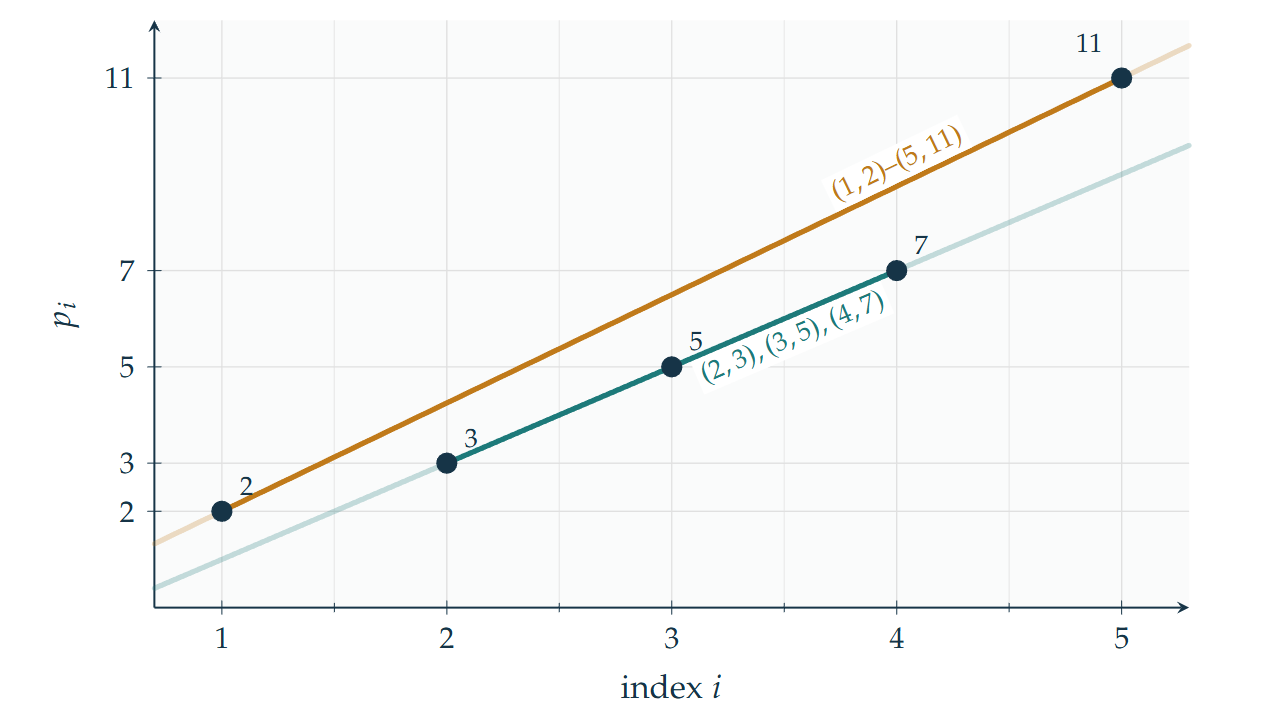
Given the first N prime-indexed points (1,p₁),(2,p₂),…,(N,pₙ)
in the plane, what is the minimum number of straight lines needed to cover all of them?
Call it f(N) — this is OEIS A373813.
The covering problem is NP-complete (Megiddo–Tamir 1982), yet across the full sweep
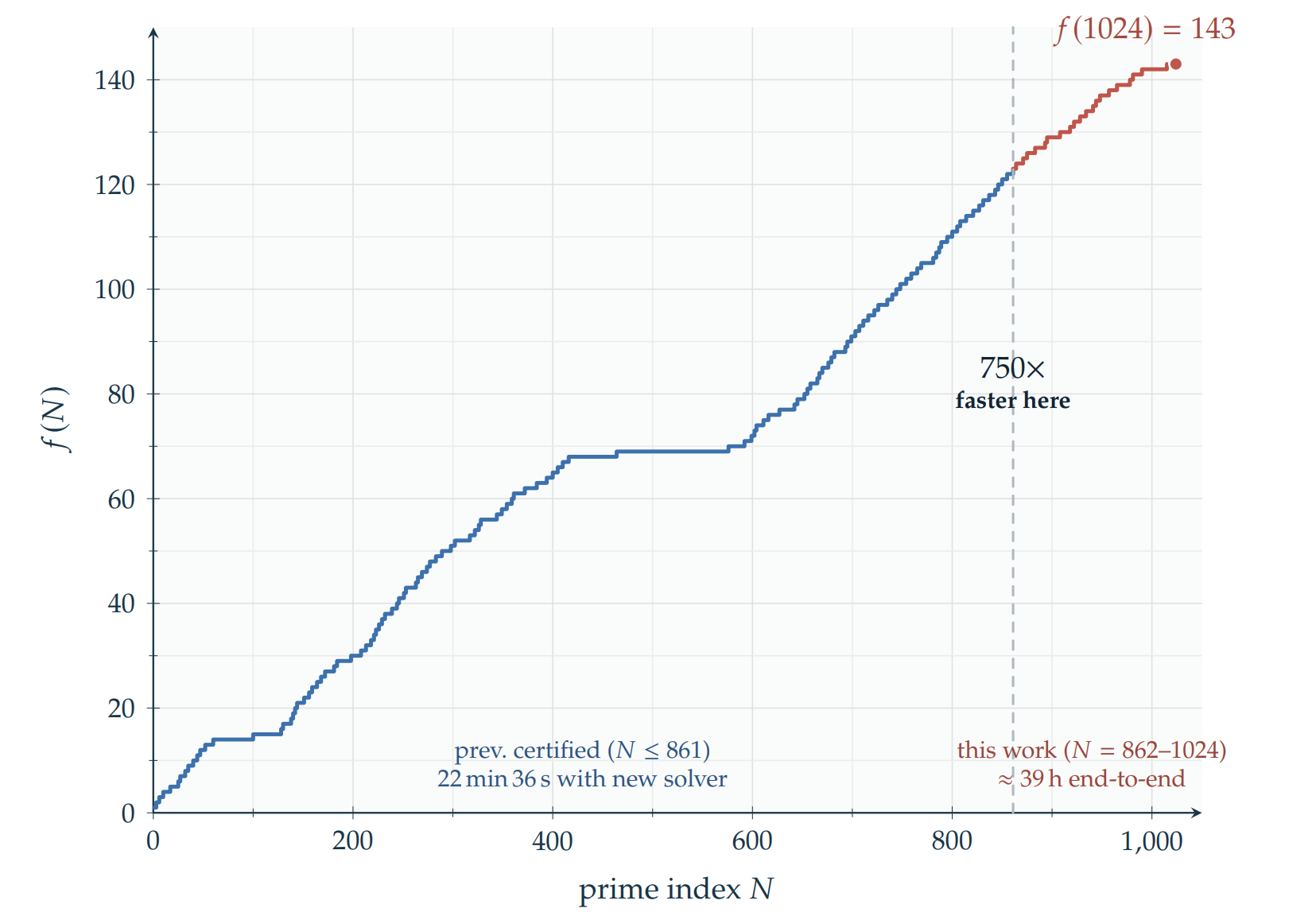
from N = 1 to N = 1024, 83% of all indices are certified with no branching at all.
The reason is structural: almost every new prime falls onto a line already present
in an optimal cover from the previous step.
The rare indices where no existing cover can absorb the new prime are called awkward primes. Each one requires a proof — via branch-and-bound with Lagrangian relaxation — that no cheaper cover exists. Certifying a single awkward prime can take hours; most of the 40-hour run time is spent on a handful of them.
This project started with the Numberphile video featuring Neil Sloane, posted April 7, 2026, which introduced the term "awkward primes." Brady Haran named p₅₇₆ = 4211 the "party-pooper prime": after 111 consecutive primes had each quietly landed on an existing cover line — the longest unbroken run recorded, from N = 465 through N = 575, certified in 111 milliseconds total — the 576th prime fell on none of them and forced f up to 70.
f(1024) = 143, Certified in Under 40 Hours
The prior certified record was f(861) = 123, reached by an industrial MIP solver in exactly 282 hours, 26 minutes, and 31.5 seconds. This solver crosses that same N = 861 boundary in 22 minutes 36 seconds — a 749.9× speedup — and then pushes on to certify f(1024) = 143: 163 newly certified, strictly optimal terms and 20 new awkward primes discovered in the process.
The full N = 1–1024 sweep completes in under 40 hours on a Google Cloud
c4d-highcpu-8 instance (8 vCPUs, 15 GB RAM), compiled with
GCC 14 -std=c++23 -O3 -march=znver5 -pthread -fno-exceptions -fno-rtti.
Source code, certified results, and exact line coordinates for all N = 1–1024 are
available on GitHub
under an MIT license, with a permanently archived release on
Zenodo.
Three Mechanisms Account for Nearly All of the Speedup
The solver uses vanilla C++23 with no external operations-research libraries. Three design decisions combine to produce the 749× speedup over a cold-starting industrial MIP solver.
First: the working set stays in L2 cache for 40 hours straight.
The 12,162 heavy lines — those passing through three or more prime-indexed points —
are enumerated once at startup in 50 milliseconds. Each is stored as a 1024-bit
coverage bitmask: sixteen contiguous uint64_t words, 128 bytes, two
cache lines. The total working set is roughly 1.5 MB. Coverage counting at every
branch-and-bound node is a popcount over a word-wise AND — a handful
of integer instructions, zero floating-point arithmetic on the hot path.
Collinearity is tested as (pⱼ − pᵢ)(k − i) = (pₖ − pᵢ)(j − i):
one integer multiply-compare.

uint64_t words (128 bytes, two cache lines) encode which prime indices the line covers: bit k lives in words[k ≫ 6] at position k mod 64. Coverage counting at every branch-and-bound node is a popcount over a word-wise AND, keeping the full 1.5 MB working set in L2 throughout the run. The filled bits here show an example line covering prime indices 3, 4, 16, 18, 19, 21, 22 — all within a single word.
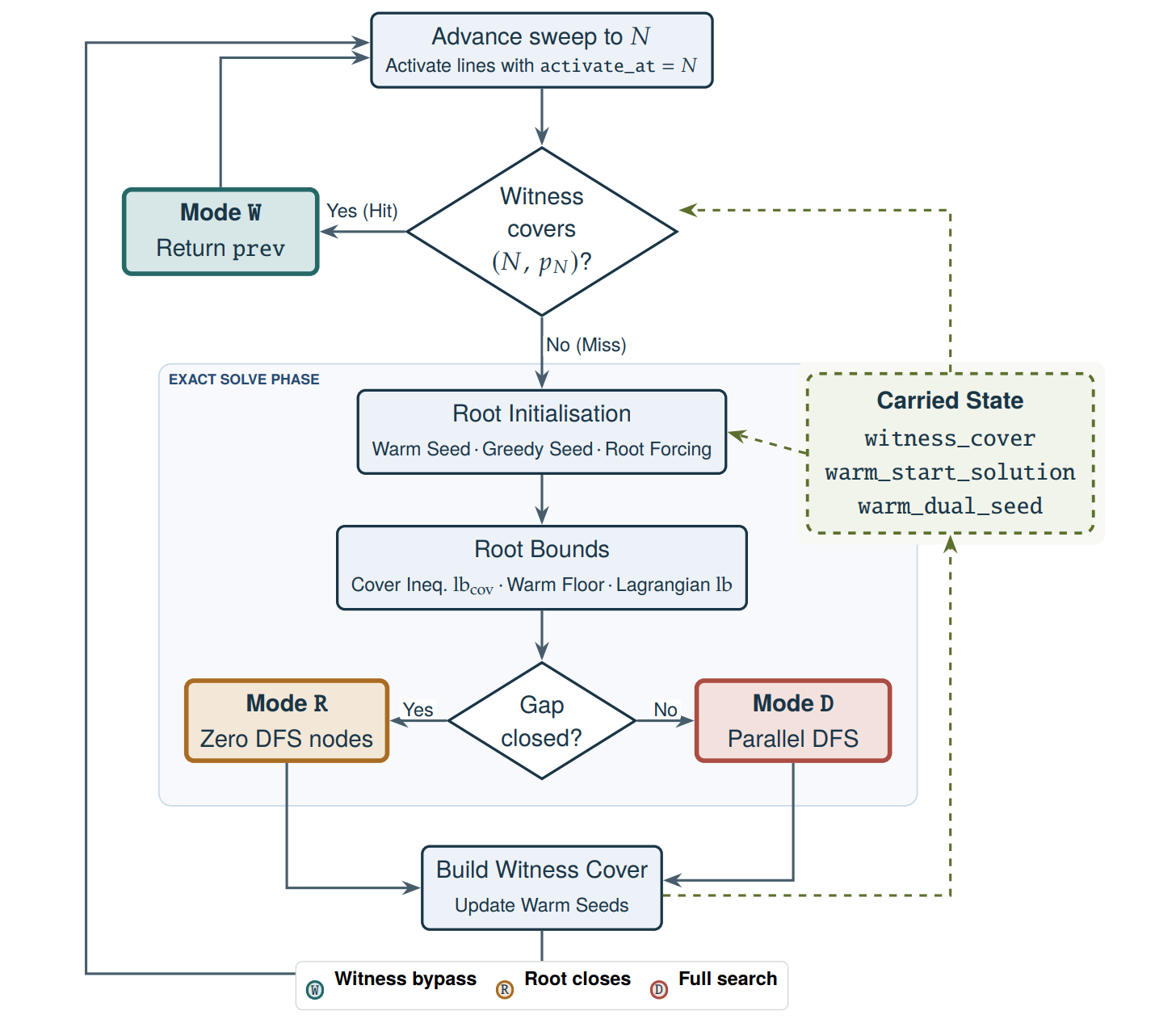
Second: warm state carries across all 1024 steps. A general-purpose MIP solver cold-starts a fresh set-cover instance at every N. This solver carries three pieces forward: a warm primal solution, a Lagrangian dual seed, and an explicit witness cover. The gain reformulation makes this structurally clean:
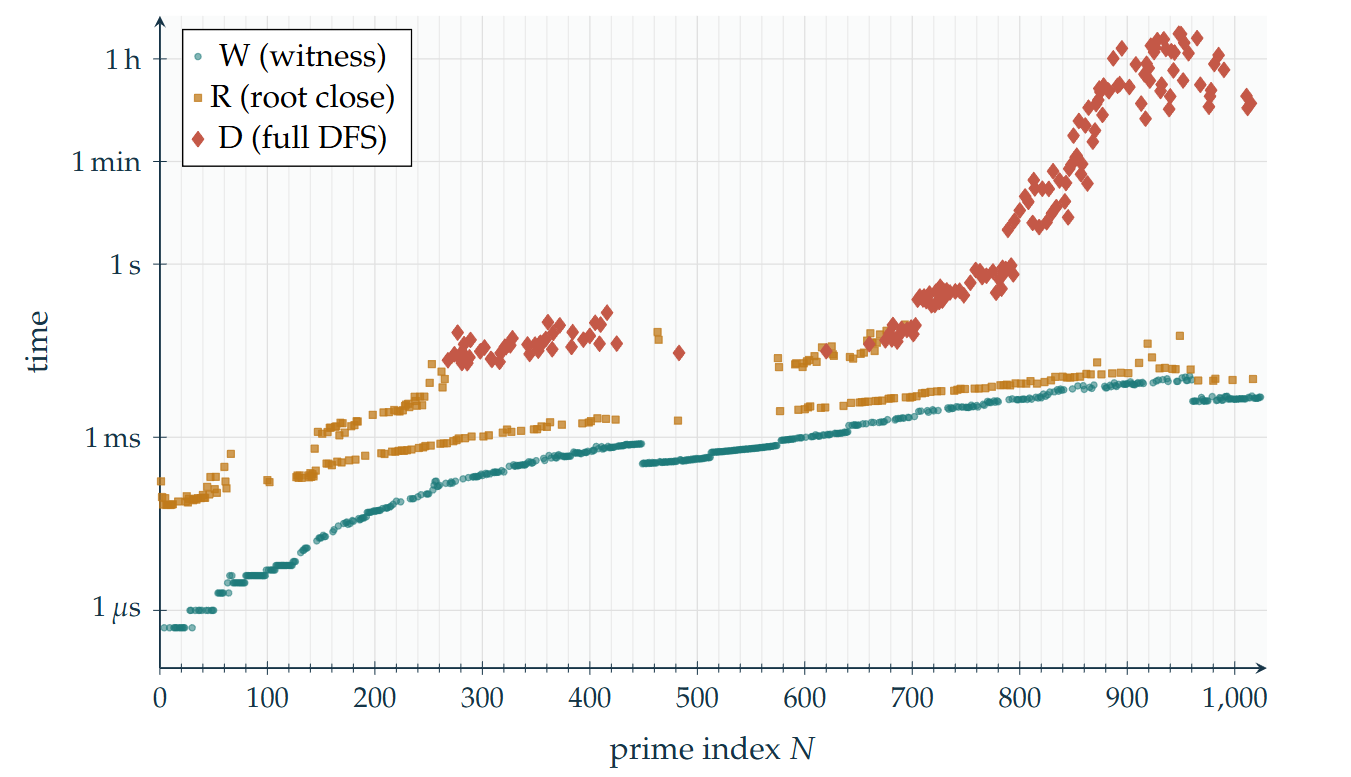
Minimising the number of lines is equivalent to maximising gain — a form that warm-starts naturally from the previous step. If the new point (N, pN) already lies on the witness cover, then f(N) = f(N − 1) is certified in O(1). Across the full 1024-step sweep: 615 witness hits (1.1 seconds total), 236 root-only closures (1.9 seconds total), and 173 full DFS runs (142,962 seconds total). The 173 DFS instances account for 99.998% of compute time while representing only 16.9% of all indices.
witness_cover, warm_start_solution, and warm_dual_seed for the next step.
Third: the Exclusive Dependency Rule — provably forced branching. If a productive heavy line has three or more uncovered points that each lie on no other productive heavy line, that line belongs to some optimal cover and may be included without any branching at all. The proof is by exchange argument: fix an optimal cover that omits the line. Those exclusively-dependent points lie on no other productive line, so they must be covered by ordinary pair or singleton lines, each handling at most two of them, requiring at least k ≥ 2 such lines. Replacing them with the forced line leaves some outside points uncovered, requiring at most ⌈k/2⌉ pair lines to restore coverage. The net cost change is Δ(k) = −k + 1 + ⌈k/2⌉. For k = 2: Δ = 0. For k = 3: Δ = 0. For k ≥ 4: Δ < 0. Hence the forced line can always replace the alternative without increasing cost.
The threshold of three is sharp. With two exclusively-dependent points, a single pair line suffices (k = 1) and Δ(1) = +1 — strictly worse, so the rule does not fire. The rule fires in chains throughout the search: in the entire N = 862–1024 block, every non-witness row had a root diagnostic gap of exactly 1 before any branching, and every certification in that block came down to closing a gap of exactly 1, never more.
Strong Branching, a Parallel Frontier, and One Crash
When the gap is exactly 1 and at least 64 points remain uncovered, strong branching evaluates a shortlist of up to four candidate lines by Lagrangian simulation and selects the variable that maximises combined child-node pruning. Strong branching fired between 3 and 18 times per DFS run in the N = 862–1024 block.
Workers pull tasks from a shared atomic counter — no mutex on the DFS hot path. Each worker owns its complete Lagrangian scratch space, undo logs, and candidate buffers. The only shared mutable state on the critical path is one atomic incumbent gain. Peak throughput reaches 65,536 parallel frontier tasks: 8 workers times an 8,192 multiplier at the hardest cover sizes.
The slowest single instance by wall-clock time was N = 948 (f = 137): 405 million branch-and-bound nodes, 9.9 billion Lagrangian iterations, 9,798 seconds. The heaviest by node count was N = 950: 511 million nodes, 12.6 billion Lagrangian iterations, 9,688 seconds, and the maximum DFS depth of 108 across all 53 full DFS runs in the new block.
One crash occurred during the run. At N = 924, with a fixed frontier multiplier
of 16,384, the solver hit the RAM ceiling mid-run. The fix: a diagnostic script
(tools/primecover_frontier_diagnosis.sh) fits a two-parameter model
to live RSS samples and prints a safe multiplier table. The final schedule runs
from a multiplier of 4 at small cover sizes up to 8,192 at f ≥ 128, with four
intermediate rungs. The multiplier governs peak memory and parallel throughput,
not correctness: any sufficiently large frontier produces a provably optimal answer.
163 Newly Certified Terms and 20 New Awkward Primes
Among the 163 newly certified terms (N = 862–1024): 89 were witness hits, 21 were root-only closures, and 53 required full DFS. Of those 53 DFS runs, 20 confirmed that f actually increased — these are the new awkward primes. The remaining 33 DFS runs confirmed that f stayed flat despite requiring full search.
The 20 new awkward primes fall at:
The current sequence ends mid-plateau: f has been stuck at 143 since N = 1015, just as f once sat at 69 from N = 464 until p₅₇₆ = 4211 forced it to 70 after 111 more primes. How long the current plateau runs is unknown.
The JavaScript implementation of the same algorithm — identical gain reformulation, witness propagation, Exclusive Dependency Rule, and Lagrangian branch-and-bound, running as a Web Worker in the demo above — reaches N ≈ 250 in about 5 seconds. The C++ solver covers the same range in 103 milliseconds, 49 times faster. Not a simplified teaching version: it is the same algorithm.
Beyond N = 1024: An Architectural Limit and an Asymptotic Question
The 1024-bit bitmask is a hard architectural limit. Extending the record beyond
N = 1024 requires widening to 2048 bits — thirty-two 64-bit words. The incremental
sweep, the Exclusive Dependency Rule, and the parallel frontier all carry over
unchanged. The natural successor is primecover2048.cpp.
The more interesting open question is whether f(N) keeps growing at a roughly constant rate — a steady staircase with random-length plateaus, with f(N) ~ cN for some positive constant c — or whether the growth rate shifts character entirely. Two effects compete. Each awkward prime adds a line to the cover, giving the next prime more rational slopes to land on; over time this accumulation should make awkward primes rarer. But prime gaps grow with N: by the prime number theorem, gaps near pN scale like log N, and each cover line can only catch a new prime when pN satisfies an exact arithmetic condition determined by that line's rational slope — a coincidence that becomes harder to hit as prime density falls. If the effects roughly cancel, f(N)/N stabilises and plateau lengths fluctuate around a finite mean. If the accumulating cover outpaces the thinning primes, awkward primes become increasingly rare and f grows sub-linearly.
The data offers no clean signal. Across N = 1–1024, f(1024)/1024 ≈ 14%, but any finite window is dominated by whichever plateau happens to be open at its boundary. Distinguishing a genuine trend from that noise requires averaging over many plateaus — and resolving the asymptotic question requires understanding how the arithmetic structure of the cover lines' rational slopes interacts with the distribution of primes in residue classes as both the cover and the prime gaps grow without bound. That is N → ∞ machinery the solver cannot supply.
This project was built by an independent researcher in Norway with no prior operations research background, over roughly 300 hours, with Claude Code and ChatGPT 5.5 in Codex. The full paper and all certified data are publicly available.
See the Algorithm Run Live in Your Browser
The same exact solver — gain reformulation, witness propagation, Exclusive Dependency Rule, Lagrangian branch-and-bound — runs as a Web Worker, right here. Forced lines lock in visually before any branch is taken.